
Context
In Oncrawl’s R&D department, we are increasingly looking to add value to the semantic content of your web pages. Using machine learning models for natural language processing (NLP), it is possible to carry out tasks with real added value for SEO.
These tasks include activities such as:
- Fine-tuning the content of your pages
- Making automatic summaries
- Adding new tags to your articles or correcting existing ones
- Optimising content according to your Google Search Console data
- etc.
The first step in this adventure is to extract the text content of the web pages that these machine learning models will use. When we talk about web pages, this includes the HTML, JavaScript, menus, media, header, footer, … Automatically and correctly extracting content is not easy. Through this article, I propose to explore the problem and to discuss some tools and recommendations to achieve this task.
Problem
Extracting text content from a web page might seem simple. With a few lines of Python, for example, a couple of regular expressions (regexp), a parsing library like BeautifulSoup4, and it’s done.
If you ignore for a few minutes the fact that more and more sites use JavaScript rendering engines like Vue.js or React, parsing HTML is not very complicated. If you want to contourn this issue by taking advantage of our JS crawler in your crawls, I suggest you read “How to crawl a site in JavaScript?”.
However, we want to extract text that makes sense, that is as informative as possible. When you read an article about John Coltrane’s last posthumous album, for example, you ignore the menus, the footer, … and obviously, you aren’t viewing the whole HTML content. These HTML elements that appear on almost all your pages are called boilerplate. We want to get rid of it and keep only a part: the text that carries relevant information.
It is therefore only this text that we want to pass to machine learning models for processing. That’s why it’s essential that the extraction is as qualitative as possible.
Solutions
Overall, we would like to get rid of everything that “hangs around” the main text: menus and other sidebars, contact elements, footer links, etc. There are several methods for doing this. We’re mostly interested in Open Source projects in Python or JavaScript.
jusText
jusText is a proposed implementation in Python from a PhD thesis: “Removing Boilerplate and Duplicate Content from Web Corpora”. The method allows text blocks from HTML to be categorized as “good”, “bad”, “too short” according to different heuristics. These heuristics are mostly based on the number of words, the text/code ratio, the presence or absence of links, etc. You can read more about the algorithm in the documentation.
trafilatura
trafilatura, also created in Python, offers heuristics on both the HTML element type and its content, e.g. text length, position/depth of the element in the HTML, or word count. trafilatura also uses jusText to perform some processing.
readability
Have you ever noticed the button in the URL bar of Firefox? It’s the Reader View: it allows you to remove the boilerplate from HTML pages to keep only the main text content. Quite practical to use for news sites. The code behind this feature is written in JavaScript and is called readability by Mozilla. It is based on work initiated by the Arc90 lab.
Here is an example of how to render this feature for an article from the France Musique website.
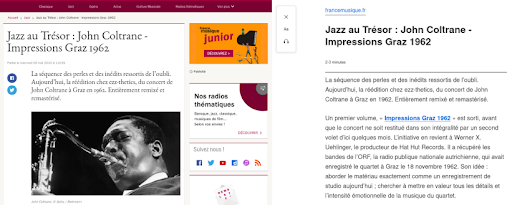
On the left, it is an extract from the original article. On the right, it is a rendering of the Reader View feature in Firefox.
Others
Our research on HTML content extraction tools also led us to consider other tools:
- newspaper: a content extraction library rather dedicated to news sites (Python). This library was used to extract content from the OpenWebText2 corpus.
- boilerpy3 is a Python port of the boilerpipe library.
- dragnet Python library also inspired by boilerpipe.
Evaluation and recommendations
Before evaluating and comparing the different tools, we wanted to know if the NLP community uses some of these tools to prepare their corpus (large set of documents). For example, the dataset called The Pile used to train GPT-Neo has +800 GB of English texts from Wikipedia, Openwebtext2, Github, CommonCrawl, etc. Like BERT, GPT-Neo is a language model that uses type transformers. It offers an open-source implementation similar to the GPT-3 architecture.
The article “The Pile: An 800GB Dataset of Diverse Text for Language Modeling” mentions the use of jusText for a large part of their corpus from CommonCrawl. This group of researchers had also planned to do a benchmark of the different extraction tools. Unfortunately, they were unable to do the planned work due to lack of resources. In their conclusions, it should be noted that:
- jusText sometimes removed too much content but still provided good quality. Given the amount of data they had, this was not a problem for them.
- trafilatura was better at preserving the structure of the HTML page but kept too much boilerplate.
For our evaluation method, we took about thirty web pages. We extracted the main content “manually”. We then compared the text extraction of the different tools with this so-called “reference” content. We used the ROUGE score, which is mainly used to evaluate automatic text summaries, as a metric.
We also compared these tools with a “home-made” tool based on HTML parsing rules. It turns out that trafilatura, jusText and our home-made tool fare better than most other tools for this metric.
Here is a table of averages and standard deviations of the ROUGE score:
| Tools | Mean | Std |
|---|---|---|
| trafilatura | 0.783 | 0.28 |
| Oncrawl | 0.779 | 0.28 |
| jusText | 0.735 | 0.33 |
| boilerpy3 | 0.698 | 0.36 |
| readability | 0.681 | 0.34 |
| dragnet | 0.672 | 0.37 |
In view of the values of the standard deviations, note that the quality of the extraction can vary greatly. The way the HTML is implemented, the consistency of the tags, and the appropriate use of the language can cause a lot of variation in the results of the extraction.
The three tools that perform best are trafilatura, our in-house tool named “oncrawl” for the occasion and jusText. As jusText is used as a fallback by trafilatura, we decided to use trafilatura as our first choice. However, when the latter fails and extracts zero words, we use our own rules.
Note that the trafilatura code also offers a benchmark on several hundred pages. It calculates precision scores, f1-score, and accuracy based on the presence or absence of certain elements in the extracted content. Two tools stand out: trafilatura and goose3. You may also want to read:
- Choosing the right tool to extract content from the Web (2020)
- the Github repository: article extraction benchmark: open-source libraries and commercial services
Conclusions
The quality of the HTML code and the heterogeneity of the page type make it difficult to extract quality content. As the EleutherAI researchers – who are behind The Pile and GPT-Neo – have found, there are no perfect tools. There is a trade-off between sometimes truncated content and residual noise in the text when not all the boilerplate has been removed.
The advantage of these tools is that they are context-free. That means, they do not need any data other than the HTML of a page to extract the content. Using Oncrawl’s results, we could imagine a hybrid method using the frequencies of occurrence of certain HTML blocks in all the pages of the site to classify them as boilerplate.
As for the datasets used in the benchmarks we have come across on the Web, they are often the same type of page: news articles or blog posts. They do not necessarily include insurance, travel agency, e-commerce etc. sites where the text content is sometimes more complicated to extract.
With regard to our benchmark and due to a lack of resources, we are aware that thirty or so pages are not sufficient to obtain a more detailed view of the scores. Ideally, we would like to have a larger number of different web pages to refine our benchmark values. And we would also like to include other tools such as goose3, html_text or inscriptis.
