
Some websites don’t make extensive use of subfolders. This might happen when, for example, a specialized CMS might produce heavily faceted search pages for filtering product pages that are all–or nearly all–located at the root directory. And that’s fine! It just means that grouping pages automatically into meaningful categories is more difficult, because many simple groupings use the subdirectories in the URL path to establish categories.
We’ve set up custom categories for multiple clients for whom our default URL segmentation doesn’t work. Here’s one of the approaches we take.
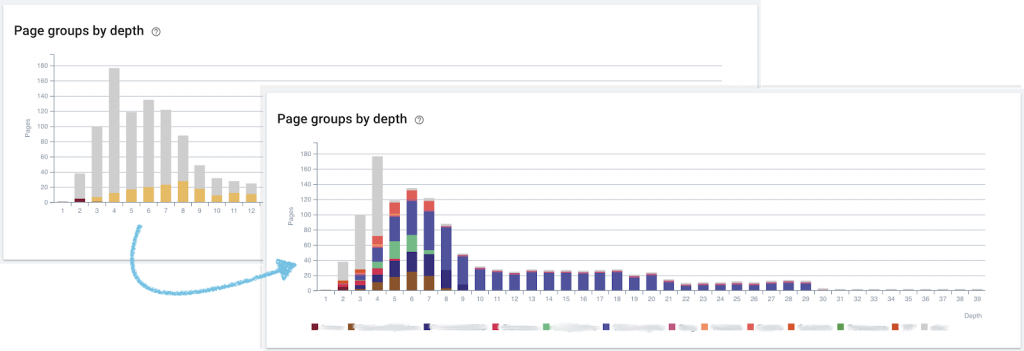
Approaching complex URLs with Oncrawl
As with any website segmentation, it helps to first define your categories. For example, if you sell tickets to live performance shows, you might know that you have pages for the following type of content:
- Artist
- Title of performance
- Auditorium
- Type of seat or ticket
- Performance language
- Your company blog on industry news
- Search landing pages that target performance genres
Once you know what categories we’re going to group your pages into, we’ll start by looking at characteristics of the URL itself. URL-based segmentations have a special advantage: they can be applied in any context and to any crawl, regardless of whether all types of data and analyses are available.
We’ll first help you look for standard usages that we can take advantage of to sort your pages:
- Do all your artist pages use certain keywords, such as “-artist-” in their URL?
- Do URLs of auditorium pages all start with the same structure, such as “-AuditoriumName-City-IdNumber-“?
Once we’ve found as many standardized structures as possible, we might then look at lists of content types that appear in URL slugs. Maybe there are ten types of ticket or seat categories, or four performance languages you specialize in, which–unlike performance titles–are unlikely to change much over time. It can sometimes be worthwhile to list these out, particularly when there is no structural element that helps us target this category.
If there are still URLs we haven’t found a way to classify at this point, we still have other options, though these may depend on additional data that isn’t available in all crawls or all analyses.
Do you keep a list of items in any particular category, such as all current performance titles or all of your landing pages, for other purposes? We can use that with data ingestion.
Do pages in some categories contain specific markup on the page itself, such as the presence of a particular of Schema.org entity, a category ID in the header, or even indications of page translations? We can scrape this markup from the page as we crawl it and put it to use.
Once we have found a way to define each category, we can define rules to create page groups based on the analysis of your URLs.
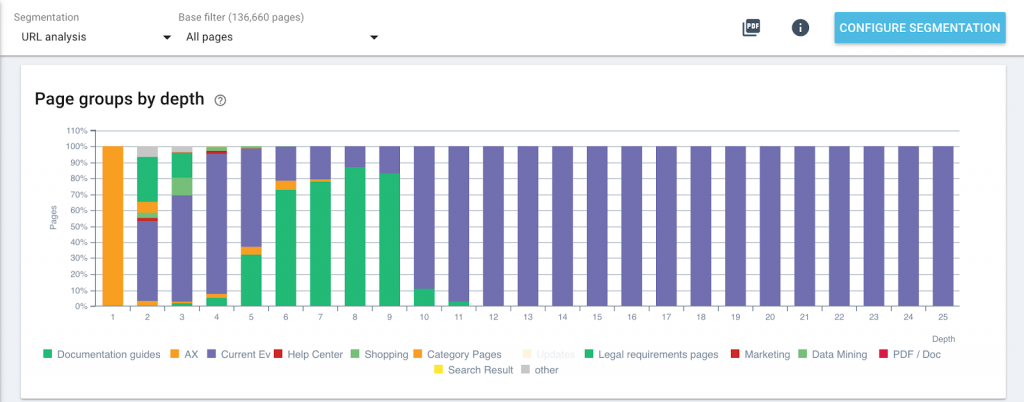
Try this at home: example page group rules
This is something you can try on your own without any risk to your data, your quotas, or your current segmentations and analyses. By creating a new segmentation, you add the ability to switch to a new categorization of your pages when viewing a crawl report. This has no impact on your data itself.
It helps to be familiar with regex (regular expressions). You can always ask our experienced CSM team for help, or keep our quick Lucene regex cheat sheet open in another tab.
In the Oncrawl application, open your project and click on “+Create segmentation” and choose to create page groups “From scratch”.
For each category group, we’ll create a page group by clicking on “+Create page group” and we’ll define a rule that describes what we know about this category’s URLs. Here are some examples.
For a “news” category with specific keywords in the URL:
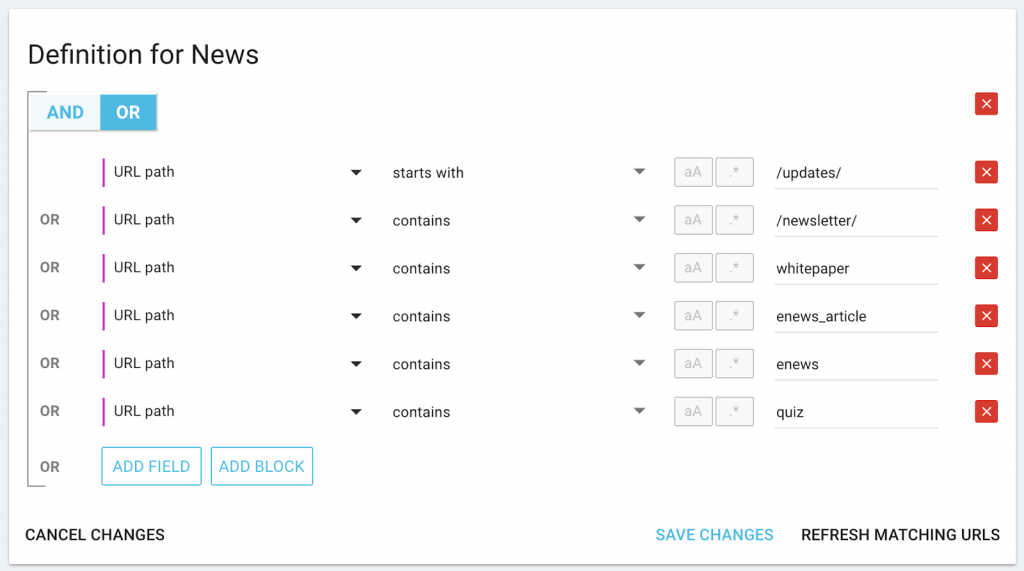
Don’t forget: you can use “starts with” if the keyword always appears at the beginning (or “ends with” if it always appears at the end) of the URL.
For categories with specific structures, like city and ID combinations (“SanDiego-406VR”), at the beginning of the URL:
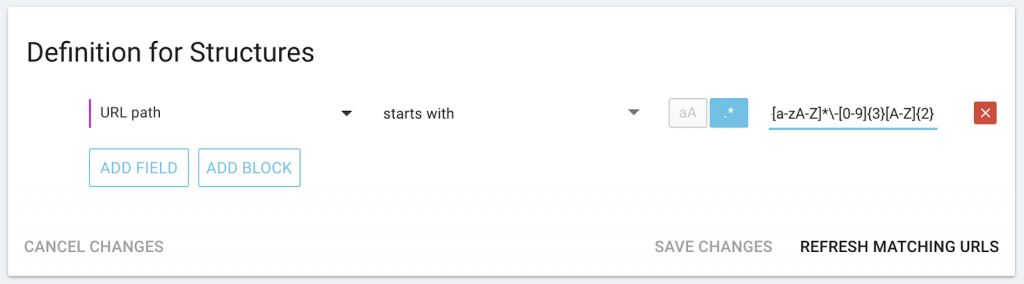
For categories with a limited list of items that must appear somewhere in the URL:
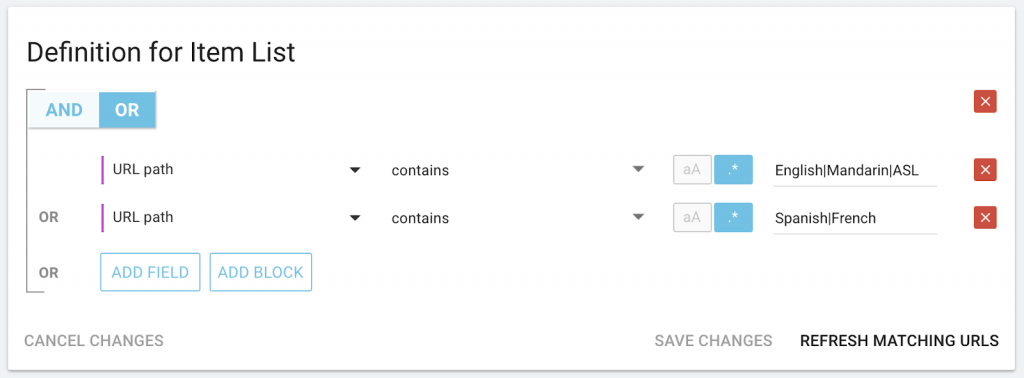
For categories based on external lists or scraped data–in this case, the performance title:
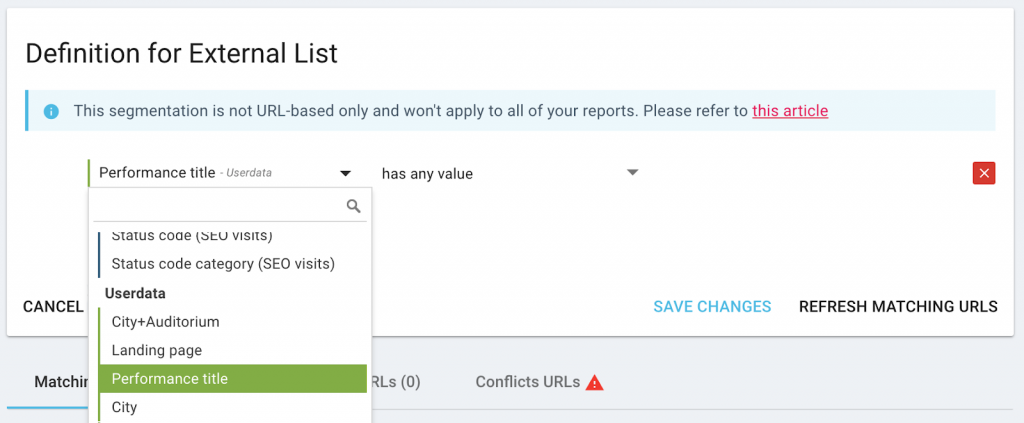
(You will need to have run a crawl that ingests or scrapes this data before creating the page group.)
It’s your turn to make your audit results speak
Don’t give up on finding a meaningful segmentation for your site, even if you can’t get useful information out of default segmentations based on subdirectories.
Creative strategies based on URL characteristics–or on any other page characteristic–can help filter pages into the right categories for an impactful overview of your analysis results.
